Within-participant behaviour PLS#
Within-participant behaviour PLS can be used to analyze trial-level associations between brain and behavioural data (e.g., subjective ratings). In this example, we will simulate a dataset where the strength of a stimulus is associated with the magnitude of an ERP on a trial-by-trial basis.
Simulating data#
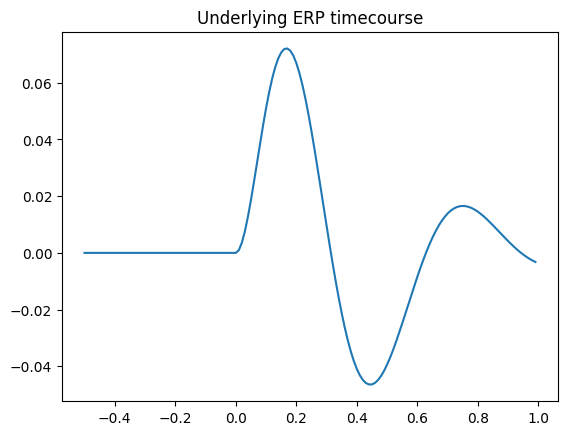
We will simulate an experiment in which a stimulus evokes a parietally focused ERP. First, we will set up the underlying ERP timecourse.
[1]:
import mne
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
import mne_plsc
np.random.seed(123)
# Set up underlying ERP timecourse
sfreq = 100
times = np.arange(-0.5, 1, 1/sfreq)
erp_timecourse = np.exp(-5*times) * times * np.sin(10*times)
erp_timecourse[times < 0] = 0
f, ax = plt.subplots()
ax.plot(times, erp_timecourse)
ax.set_title('Underlying ERP timecourse')
[1]:
Text(0.5, 1.0, 'Underlying ERP timecourse')
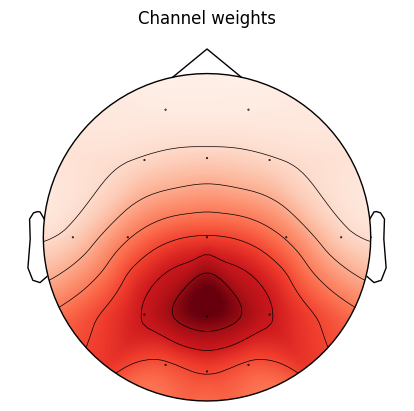
Next, we will set up the weights that will determine how strongly the ERP will be expressed at each channel.
[2]:
# Set up montage and info
montage = mne.channels.make_standard_montage('biosemi16')
ch_pos_dict = montage.get_positions()["ch_pos"]
ch_pos_array = np.array([ch_pos_dict[ch] for ch in montage.ch_names])
info = mne.create_info(ch_names=montage.ch_names,
ch_types='eeg',
sfreq=sfreq)
info = info.set_montage(montage)
# Function to get channel weights
center = ch_pos_dict['Pz']
dist = np.linalg.norm(ch_pos_array - center, axis=1)
chan_weights = np.exp(-(dist ** 2) / (2 * 0.075 ** 2))
f, ax = plt.subplots()
mne.viz.plot_topomap(chan_weights, info, axes=ax, show=False)
ax.set_title('Channel weights')
plt.show()
Finally, we will simulate the actual epochs per participant.
[3]:
n_ptpts = 5
trials_per_ptpt = 20
all_epochs = []
for ptpt_n in range(n_ptpts):
# Project ERP onto channels
data = np.outer(chan_weights, erp_timecourse)
data = np.stack([data]*trials_per_ptpt)
# Simulate stimulus
stim = np.random.gamma(shape=1, scale=1, size=(trials_per_ptpt,))
# Scale ERP by stimulus
data = data * stim.reshape((-1, 1, 1))
# Add noise
noise = 0.1*np.random.normal(size=data.shape)
data = data + noise
# Create epochs object
epochs = mne.EpochsArray(data=data,
info=info,
metadata=pd.DataFrame({
'stim': stim.squeeze(),
'cond': [0, 1]*int(trials_per_ptpt/2)}),
verbose=False)
all_epochs.append(epochs)
Fitting and evaluating the model#
Having set up the data, the syntax for fitting a within-participants behaviour PLS model is similar to fitting an ordinaly within-participants PLS model. The difference is that we don’t provide a design matrix—we just specify the name(s) of the columns in each participant’s metadata containing the covariate(s).
[4]:
res = mne_plsc.fit_within_beh(data=all_epochs,
covariates='stim')
res.plot_lv(0)
[4]:
(<Figure size 640x480 with 3 Axes>,
array([<Axes: xlabel='Time (s)', ylabel='Salience'>,
<Axes: ylabel='Correlation with brain score'>], dtype=object))
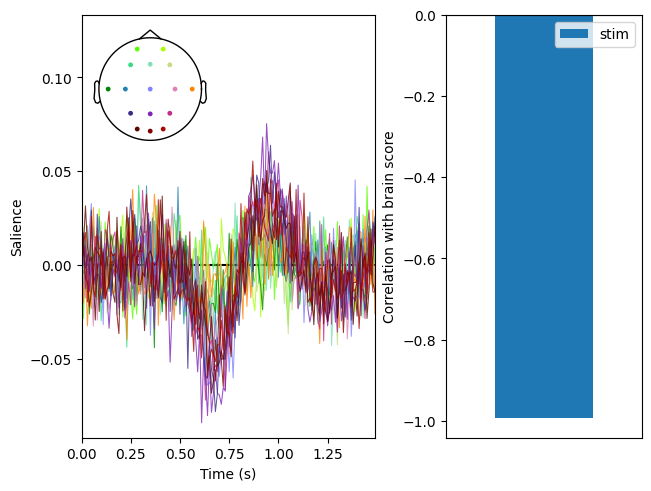
Unsurprisingly, the latent variable is significant:
[5]:
res.permute(100)
print(res.summary())
Getting permutations: 100%|██████████| 5/5 [00:00<00:00, 1295.98it/s]
Permuting: 100%|██████████| 100/100 [00:00<00:00, 659.25it/s]
LV index singular value variance explained p value
0 0 7.537496 1.0 0.009901
Cluster analysis#
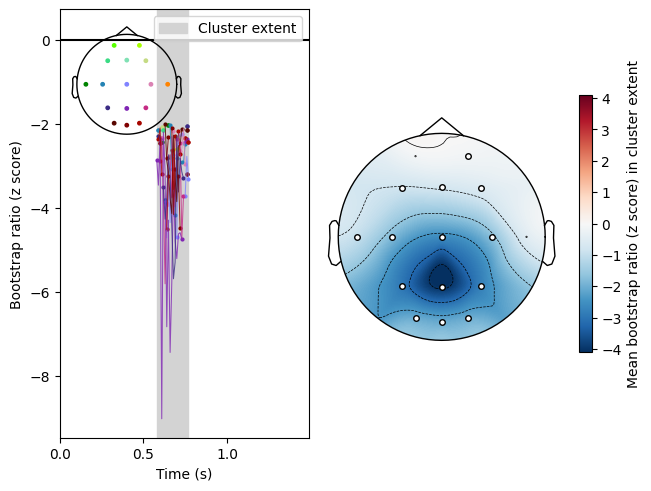
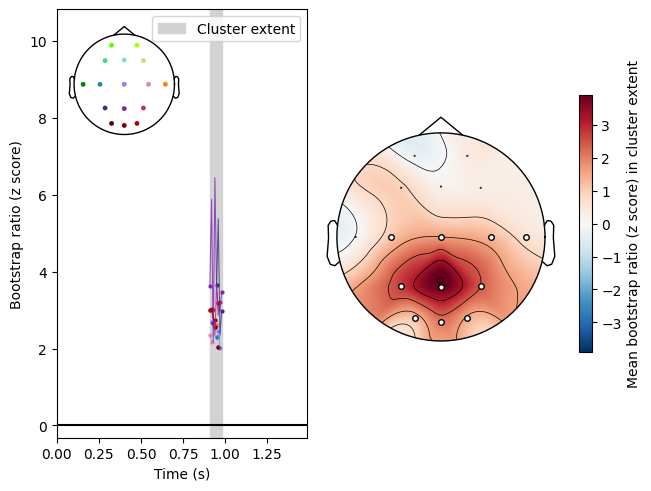
Cluster analysis produces parietal clusters, as expected given how the data was simulated:
[6]:
res.bootstrap(100)
res.add_adjacency(montage_name='biosemi16')
res.cluster()
res.plot_cluster(lv_idx=0, cluster_idx=0, highlight='extent')
res.plot_cluster(lv_idx=0, cluster_idx=1, highlight='extent')
Getting participant resamples: 100%|██████████| 100/100 [00:00<00:00, 27151.11it/s]
Getting trial resamples: 100%|██████████| 5/5 [00:00<00:00, 103.56it/s]
Resampling: 100%|██████████| 100/100 [00:00<00:00, 441.40it/s]
Defaulting to all channels adjacent for ERP/ERF analysis
Clustering z-scores
Defaulting to unsigned clustering
Computing clusters for lv_idx 0...
Threshold: 2
45 clusters
[6]:
(<Figure size 640x480 with 4 Axes>,
array([<Axes: xlabel='Time (s)', ylabel='Bootstrap ratio (z score)'>,
<Axes: >], dtype=object))