Mean-centred ERP analysis#
This example will show how to use mean-centred PLS for analyzing ERP data. We will use the MNE example data, in which a single participant viewed visual stimuli presented to the left or right visual field, or heard auditory stimuli presented to the left or right ear. Following the MNE example here, we will compare the left visual and auditory stimuli.
Loading the data#
We will begin by loading the necessary libraries and epoching the data. The details of creating epochs are covered in the MNE example.
[1]:
import mne
import mne_plsc
sample_data_folder = mne.datasets.sample.data_path()
sample_data_raw_file = sample_data_folder / "MEG" / "sample" / "sample_audvis_filt-0-40_raw.fif"
raw = mne.io.read_raw_fif(sample_data_raw_file)
events = mne.find_events(raw, stim_channel="STI 014")
raw.pick(["eeg", "eog"]).load_data()
raw.crop(tmax=90)
events = events[events[:, 0] <= raw.last_samp]
event_dict = {
"auditory/left": 1,
"visual/left": 3,
}
epochs = mne.Epochs(
raw,
events,
event_id=event_dict,
tmin=-0.2, tmax=0.5,
preload=True
)
reject_criteria = dict(eog=200e-6)
epochs = epochs.drop_bad(reject=reject_criteria)
epochs = epochs.pick('eeg')
Using default location ~/mne_data for sample...
Fetching 1 file for the sample dataset ...
Downloading file 'MNE-sample-data-processed.tar.gz' from 'https://osf.io/download/86qa2?version=6' to '/home/docs/mne_data'.
Untarring contents of '/home/docs/mne_data/MNE-sample-data-processed.tar.gz' to '/home/docs/mne_data'
Download complete in 01m00s (1576.2 MB)
Opening raw data file /home/docs/mne_data/MNE-sample-data/MEG/sample/sample_audvis_filt-0-40_raw.fif...
Read a total of 4 projection items:
PCA-v1 (1 x 102) idle
PCA-v2 (1 x 102) idle
PCA-v3 (1 x 102) idle
Average EEG reference (1 x 60) idle
Range : 6450 ... 48149 = 42.956 ... 320.665 secs
Ready.
Finding events on: STI 014
319 events found on stim channel STI 014
Event IDs: [ 1 2 3 4 5 32]
Reading 0 ... 41699 = 0.000 ... 277.709 secs...
Not setting metadata
61 matching events found
Setting baseline interval to [-0.19979521315838786, 0.0] s
Applying baseline correction (mode: mean)
Created an SSP operator (subspace dimension = 1)
1 projection items activated
Using data from preloaded Raw for 61 events and 106 original time points ...
1 bad epochs dropped
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
3 bad epochs dropped
Fitting the model#
To fit the model, we need to first determine which epochs are from which condition. To do so, we can use the get_epoch_labels function from mne_plsc.utils:
[2]:
labels = mne_plsc.utils.get_epoch_labels(epochs)
Next, we can fit a model to the data and visualize it. Although the labels are within-participant labels, we will provide them as the “between” argument since the unit of observation for a single-subject analysis is trials:
[3]:
res = mne_plsc.fit_mc(epochs, between=labels, random_state=123)
res.plot_lv(0)
[3]:
(<Figure size 640x480 with 3 Axes>,
array([<Axes: xlabel='Time (s)', ylabel='Salience'>,
<Axes: ylabel='Brain score'>], dtype=object))
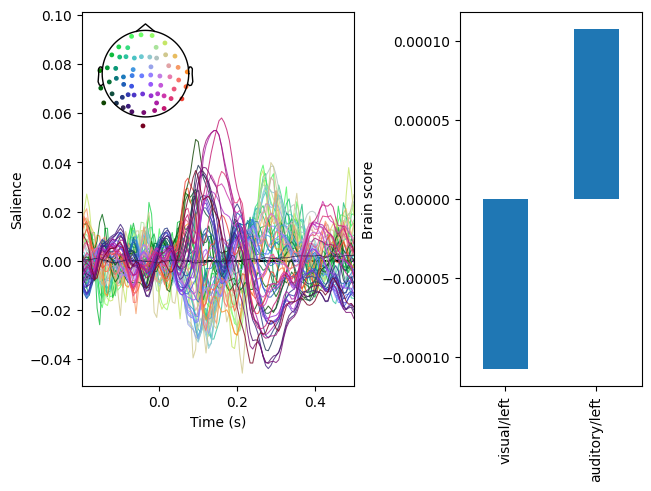
In the plot above, the right panel displays a multivariate pattern of activity that differentiates between the conditions. The left panel indicates how strongly the pattern is expressed in each condition.
Assessing model significance#
To assess the significance of the model, we can run permutation testing. For speed, we will only do 100 permutations here. For real data, it is advisable to do many more.
[4]:
res.permute(100)
print(res.summary())
res.plot_scree()
Getting permutations: 100%|██████████| 100/100 [00:00<00:00, 83886.08it/s]
Permuting: 100%|██████████| 100/100 [00:00<00:00, 1722.15it/s]
LV index singular value variance explained p value
0 0 0.000152 1.0 0.019802
1 1 0.000000 0.0 NaN
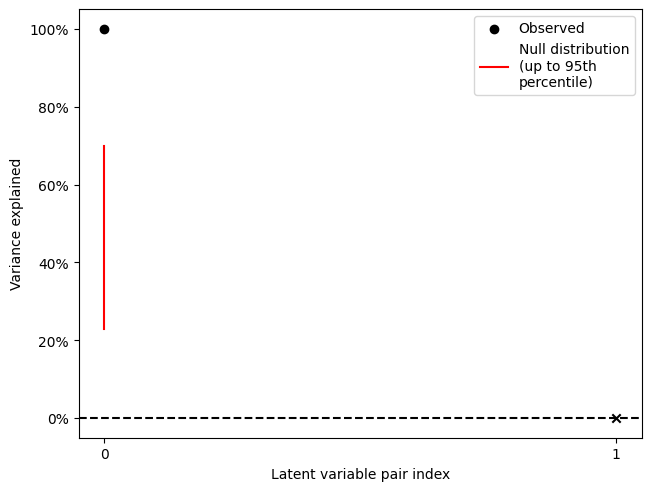
Thus, the comparison between auditory and visual stimuli is significant. Note that although the decomposition yields 2 latent variable pairs, the second \(p\) value is NA (corresponding to the “x” on the scree plot). This is because the rank of the decomposed matrix is one for this mean-centred analysis due to the mean-centering step.
Cluster analysis#
To characterize the latent variable pair, we can run bootstrap resampling and cluster the \(z\) scores. For speed, we will run 100 resamples; for real data, it would be advisable to do many more.
[5]:
res.bootstrap(100)
Getting resamples: 100%|██████████| 100/100 [00:00<00:00, 10079.31it/s]
Resampling: 100%|██████████| 100/100 [00:00<00:00, 850.01it/s]
Before cluster analysis, it is necessary to add an adjacency matrix to the data. In the case of ERP analysis, it generally makes sense to treat all channels as adjacent in order to detect multi-channel patterns. This is the default behaviour of .add_adjacency() but can be changed with the all_channels_adjacent argument.
[6]:
res.add_adjacency()
res.cluster(threshold=4, which='z-scores')
Defaulting to all channels adjacent for ERP/ERF analysis
Defaulting to unsigned clustering
Computing clusters for lv_idx 0...
Threshold: 4
3 clusters
Plotting the cluster sizes shows us that, of the three clusters, only two account for a major proportion of the strong saliences:
[7]:
f, ax = res.plot_cluster_sizes(lv_idx=0)
ax.axhline(y=10, c='k', ls=':')
[7]:
<matplotlib.lines.Line2D at 0x7c9f29ce3910>
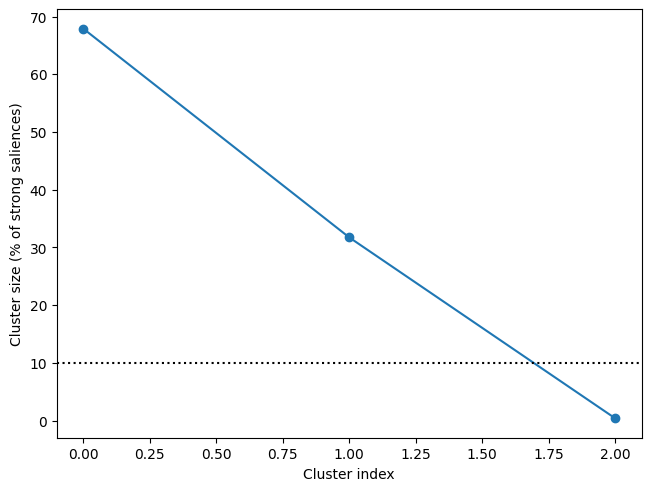
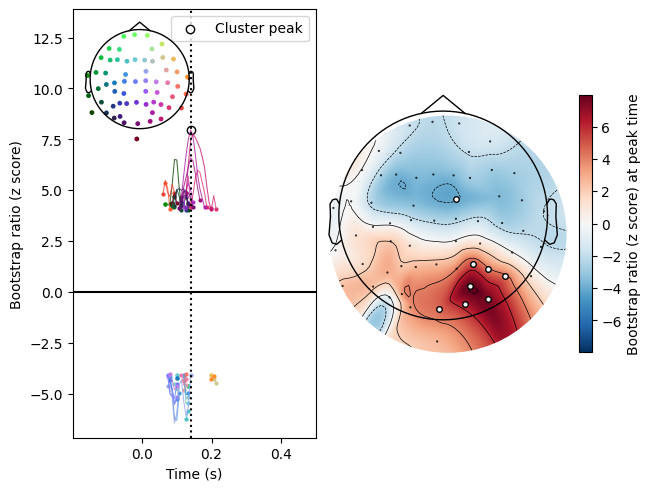
We can plot both of them using the .plot_clusters() method. Note the similarity of the topomaps here to those in the MNE tutorial.
[8]:
res.plot_cluster(lv_idx=0, cluster_idx=0)
res.plot_cluster(lv_idx=0, cluster_idx=1)
[8]:
(<Figure size 640x480 with 4 Axes>,
array([<Axes: xlabel='Time (s)', ylabel='Bootstrap ratio (z score)'>,
<Axes: >], dtype=object))
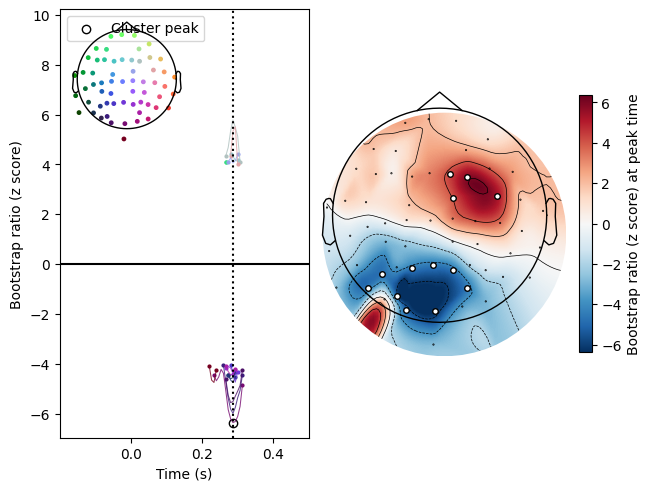
Note also that both positive and negative saliences can be included in the same cluster. This is the default setting for clustering ERP/ERF data, since positive and negative deflections are often considered part of the same component when they occur simultaneously. This can be adjusted using the signed argument to cluster(): with signed=True, positive and negative saliences cannot be part of the same cluster.